The menu features several options for Find and Replace. The → (Ctrl-F) and → (Ctrl-H) menu items will simply start their corresponding dialogs described in Section 10, “Basic Find and Replace”.
The → (Ctrl-G) menu item will repeat the last used search. It will continue the search after the position where the previous search was stopped. If the end of file is reached, it will signaled it if the search operates on a unique file, nevertheless you can continue the search from the top of file with Ctrl-G after dismissing the Search: no match found dialog. If the search operates on multiple files, it will continue with the next file.
Here you can see how the Find again process operates on two successive searches for the word "url" in an xml file:


The → menu item will search for the currently selected text. If you select for example the name of a function, in bluefish, or in any other program, and you choose find from selection Bluefish will start a new search for this selected string.
Here we have selected a function in a C file:
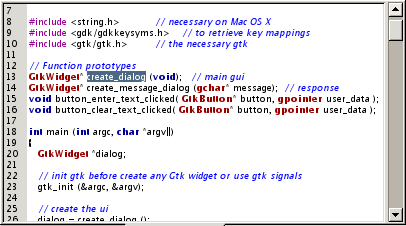
Clicking on → gives the following result:
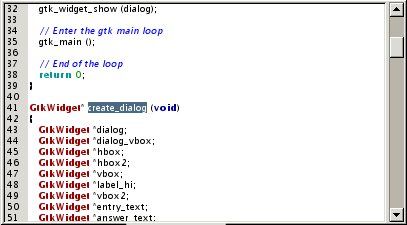
Next occurrences of the string can be found with Ctrl-G as usual.
With find and replace you can do incredibly powerful searches. We have already seen some of them in Section 4.1, “Generating several bookmarks at once”, which deserve some explanation here.
Example VI.1. Retrieving all sections in an xml book
The regular POSIX expression <sect[0-9]+ id="[^"]+"> can be split into:
<sect: a string beginning by<sect[0-9]+: followed by one or more (the+part) characters in the range of 0 to 9 (the[0-9]part), i.e. digits, followed by a spaceid=": followed by the stringid, followed by an equal sign, followed by a double-quote[^"]+: followed by one or more (the+part) not double-quote characters (the[^"]part -^is a not )">: followed by a double-quote, and ending with a > sign
Therefore, it matches any string of type <sectn id="nameofthesection">, where n is a positive integer.
Example VI.2. Retrieving all functions in an Objective C file
In a simplified example, an objective C function may have two forms:
- (IBAction)nameofthefunction:(id)parameter- (void) nameofthefunction
We will try to make a pattern from those forms:
Hyphens and parentheses have special meanings in regular expressions, hence we need to escape them, i.e. to put before each of them a backslash, so that they will be interpreted as normal characters.
Thus,
- (is matched by:\- \(IBActionorvoidare a non empty sequence of alphabetical characters. We have already seen something similar in the previous example.They are matched by:
[a-z]+, that is one or more characters in the range of a to z.Another parenthesis matched by:
\).A space or no space at all, it is matched by:
*, that is a space followed by an asterisk, which means 0 or more times the preceding character.A non empty sequence of characters, matched by
[a-z]+as already seen.A colon or no colon at all, which is matched by:
[:]*.
Thus the whole POSIX regular expression is: \- \([a-z]+\) *[a-z]+[:]*. In the example, we have grouped the parts with parentheses, you may prefer this simplified form, though it is not recommended.
Example VI.3. Retrieving all functions in a PHP file
A php function has the form function nameofthefunction(listofparameters), where the list of parameters can be empty. To match it with a PERL regular expression, you have to know that \s matches any white space and \w matches any alphanumerical character as well as white spaces.
Thus, the matching regular expression is: function\s+\w+.
Now, if you want to capture also the function's parameters, you have to add:
An opening parenthesis:
\(. Remember parentheses should be escaped with a backslash.Zero or more characters, none of them being a closing parenthesis:
[^\)]*A closing parenthesis: \)
The PERL regular expression becomes: function\s+\w+\([^\)]*\).
Here is a new example which transforms a table into a definition list inside an html file.
Example VI.4. Transforming a table into a definition list
Say you have the following table:

You want to transform it in the following definition list:

For the rendering, you will use the following css style sheet:
.st2 {
font-weight: 900;
color: #e38922;
margin-left: 30px;
}
dl {
font-weight: 900;
margin-left: 55px;
}
dt {
margin-top: 6px;
}
.dd1 {
font-style: normal;
font-weight: 400;
}
The table's source code is the following:
<table border="1"> <tr> <th>Software</th> <th>Use</th> <th>Requirements</th> <th>Author</th> <th>Date</th> <th>Download</th> </tr> <tr> <td>BackupSeek 1.8</td> <td>To catalog your backup from all media. Prints labels too.</td> <td>PPC</td> <td>Ken Ng</td> <td>17 November 1999</td> <td>English version (452 Ko)</td> </tr> <tr> <td>Biblioteca v. 1.0</td> ... </tr> </table>
The definition list's source code will be the following:
<p class="st2">BackupSeek 1.8</p> <dl> <dt>Use:</dt><dd><span class="dd1">To catalog your backup from all media. \ Prints labels too.</span></dd> <dt>System requirements:</dt><dd><span class="dd1">PPC</span></dd> <dt>Author:</dt><dd><span class="dd1">Ken Ng</span></dd> <dt>Date:</dt><dd><span class="dd1">17 November 1999</span></dd> <dt>Download:</dt><dd><span class="dd1">English version (452 Ko)</span></dd> </dl> <p class="st2">Biblioteca v. 1.0</p> ... </dl>
Comparing both chunks of code, we see that the variable sequence of characters to capture is the one between one <td> tag and its closing </td> tag. That sequence can be interpreted as one or more characters which are not a <. We have already seen that. This is expressed as: [^<]+
To be able to retrieve it later, we need to embed it into parentheses. Thus, the string becomes: ([^<]+)
Next, this sequence is embedded into <td> and </td>, which is expressed simply concatenating the strings: <td>([^<]+)</td>
We should also add the end of line character, which is expressed as: \n. The regular expression now describes a whole line: <td>([^<]+)</td>\n
As we cannot use variables to retrieve the headers of the table, we will merely repeat that string five times, so that the regular expression matches exactly the six lines of importance to us.
![[Note]](imgs/note.png) | |
Do not type it six times in the search field. Select the string, use the shortcuts Ctrl-C to copy it, move to the end of the string with the right arrow, and use Ctrl-V five times to paste it at the end of the string. |
The regular expression becomes (backslashes are inserted at end of line just for the purpose of not to have too long lines):
<td>([^<]+)</td>\n \ <td>([^<]+)</td>\n \ <td>([^<]+)</td>\n \ <td>([^<]+)</td>\n \ <td>([^<]+)</td>\n \ <td>([^<]+)</td>\n
Those lines are at their turn embedded into <tr> and </tr> tags each of them on their own line, which can be expressed as: <tr>\n for the first one, and </tr>\n for the second one. We add those strings respectively at the beginning and at the end of our regular expression, which becomes:
<tr>\n \ <td>([^<]+)</td>\n \ <td>([^<]+)</td>\n \ <td>([^<]+)</td>\n \ <td>([^<]+)</td>\n \ <td>([^<]+)</td>\n \ <td>([^<]+)</td>\n \ </tr>\n
Now that we have described the search pattern, we will build the replace pattern. Each expression embedded into parentheses in the search string can be retrieved with \x, where x is an integer starting at 0 for the first expression, 1 for the second, etc. All others parts in the final string are fixed strings which we will express as they are.
The first line becomes (note the \n at the end to match the end of line character):
<p class="st2">\0</p>\n
The second line (again, note the \n to match the end of line characters):
<dl>\n<dt>Use:</dt><dd><span class="dd1">\1</dd>\n
And finally the whole replace pattern is:
<p class="st2">\0</p>\n \ <dl>\n<dt>Use:</dt><dd><span class="dd1">\1</dd>\n \ <dt>System requirements:</dt><dd><span class="dd1">\2</span></dd>\n \ <dt>Author:</dt><dd><span class="dd1">\3</span></dd>\n \ <dt>Date:</dt><dd><span class="dd1">\4</dd>\n \ <dt>Download:</dt><dd><span class="dd1">\5</span></dd>\n</dl>\n
After entering both patterns, choose PERL type in the Regular expression drop down list, check the Patterns contain backslash escape sequences (\n, \t) and click OK.
After replacement occurred, you have to remove the table headers and the last </table> tag and to insert the link to the style sheet.
Note that if some lines contain a < sign, the table row will not be translated, but others will.
In the Find and Replace dialogs it is not possible to insert the keys Enter or Tab. A simple way to do it is to copy two lines in a row from the current document into the Find or Replace dialog, this way you retrieve the end of line character. The same applies for Tab. A more elaborated way to do it is to use escaped characters to represent these characters. A new line character, produced by pressing the Enter key, is represented as \n. Use \t for a tab. To get an actual backslash, just escape the backslash, \\. There are many other escape characters used in regular expressions.
| |
To enable the escaped characters in your searches check the Patterns contain backslash sequences (\n, \t) option. |
If you have any search and replace patterns you use often, you can also add them to the Custom Menu. Check Section 7, “Custom menu” for more information.
For more information about regular expressions you might want to read man 1 perlre, man 3 pcrepattern, man 3 regex or man 7 regex, or read any of the great Internet sites about regular expressions. As you become more familiar with regular expressions, you will realize that they make Bluefish a very powerful editor.